
データなし
コード銘柄名
現在値変化額変化率出来高売買代金始値前日終値高値安値時価総額浮動株時価株式総数浮動株5日変化率10日変化率20日変化率60日変化率120日変化率250日変化率年初来配当利回売買回転率直近PER前年PER振幅業種
お気に入りデモ取引




データなし
来週の【重要イベント】米ISM製造業、景気動向指数、米雇用統計 (2月3日~9日)
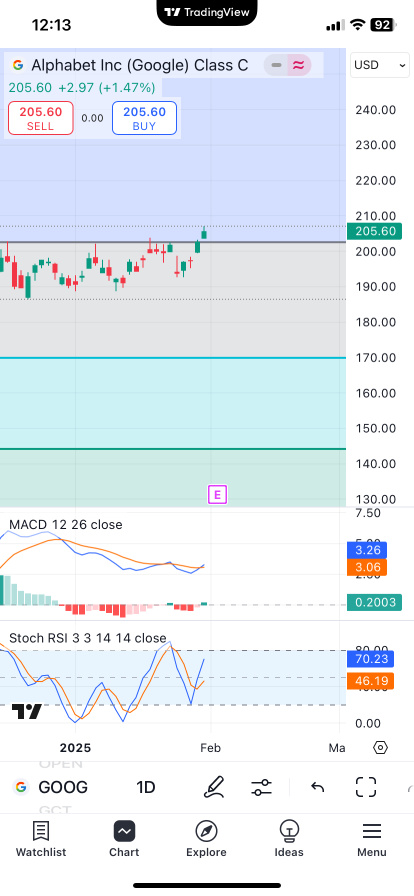
アルファベット社(GOOGL):人工知能駆動の広告成長の先駆者
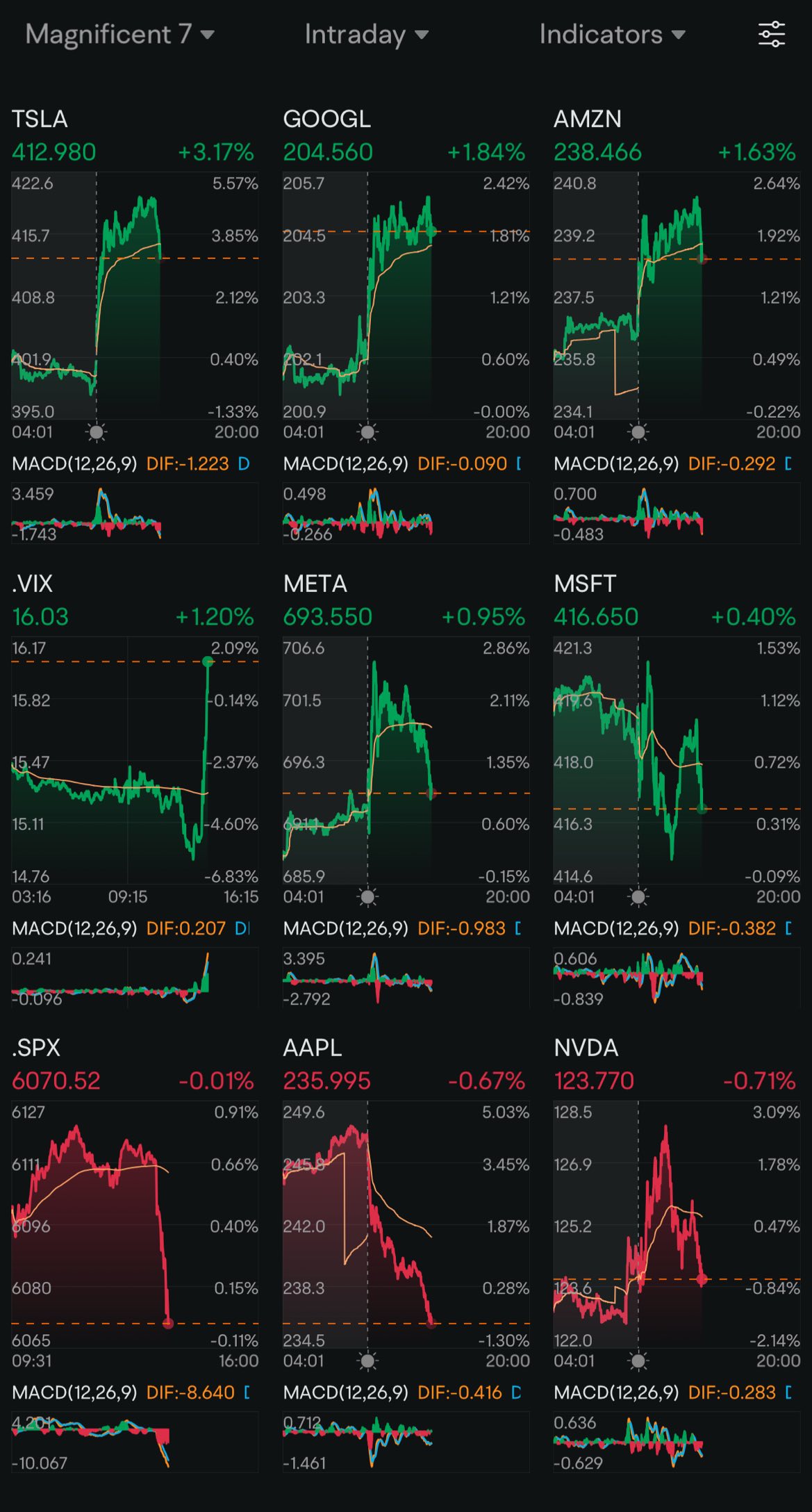
1月31日の米国株の売買代金トップ20:バークレイズはテスラの株価が基本面から乖離していると述べた
金曜日、米国株の売買代金第1位はエヌビディアで、下落率は3.67%、売買代金は474.39億ドルでした。今週、その株は累計で15.81%下落しました。中国のAIスタートアップDeepSeekが高性能低コストの大言語モデルを発表した後、AIへの資本支出の論理が疑問視され、関連する株式は普遍的に圧力を受けています。エヌビディア社は、金曜日(1月31日)に、DeepSeek-R1モデルがNVIDIA NIMのマイクロサービスのプレビュー版として、エヌビディアが開発者向けに提供するウェブサイトで公開されたと発表しました。DeepSeek-R1 NIMマイクロサービスは、単一のエヌビディアHGXで動作します。
【米国株31日の注目銘柄】シリウスXMホールディングスが上昇
ウィークリーバズ:なんて素晴らしいニュースの週だ
投資家の皆さん、良い週末を!Weekly Buzzへようこそ。今週のmoomooで話題の株式トップテンについてお話しします!賞を獲得するチャンスのために、下のWeekly Topicの質問にコメントしてください!
ウォール街の今日:金曜日は誰かが「関税」と言う前までは素晴らしかった
市場は金曜日の朝に上昇で始まりました。インフレデータが価格が間違った方向に向かっていることを示したにもかかわらず、トランプ大統領が関税警報を鳴らす役割でほぼ毎日の報復を行っています。トランプは、2月から友好国と敵国の両方に20〜30%の関税を課すと述べています。








bullbearnme : 中国製
Timothy RKT : DeepSeekの返信:**DeepSeek 人工知能の開発および知的財産に関する改訂分析:**
中国の企業DeepSeek Inc.(2023年設立)が開発したDeepSeek人工知能は、人工知能の既存の進歩を基に構築する一般的な業種の実践を具体化しています。大規模な言語モデル(LLMs)のほとんどと同様に、DeepSeekは、Googleが2017年に導入した基本的なフレームワークであるtransformerアーキテクチャを活用し、MetaのLLaMAやHugging FaceのBLOOMなどのオープンソースプロジェクトからの手法を取り入れています。このアプローチは、AIの開発において、完全に新しいアーキテクチャをゼロから作成するのではなく、段階的な革新が一般的であるため標準的です。
**明確化の重要なポイント:**
1. **基盤とオープンソースの依存関係:**
DeepSeekはオープンソースのフレームワークを利用する可能性がありますが、ChatGPTのようなプロプライエタリモデルの直接使用を示唆する公開証拠はありません(非オープンソースであるChatGPTは除く)。その代わり、その開発はおそらく、公に利用可能なモデルの微調整や適応を含んでいたと考えられており、これは多くのオープンソースライセンス(例:LLaMAの非商用ライセンス)で許可されている実践です。「ChatGPTに類似した要素」の主張は、コードやデータの複製ではなく、transformerベースのLLMの出力に関する広範な類似点に由来する可能性があります。
2. **トレーニングデータと著作権の懸念:**
DeepSeekはほとんどのLLMと同様に、公共のインターネットソースから引き出された大規模なデータセットでトレーニングされた可能性がありますが、これには著作権のあるテキスト、学術論文、フォーラムの議論などが含まれる可能性があります。これはデータの由来や知的財産法との遵守に関する倫理的および法的な問題を引き起こし、特に未許可の使用に関して、AI業種全体における体系的な問題を提起します。ただし、これらの問題はDeepSeekに特有のものではなく、中国のAI企業はデータのガバナンスポリシーの曖昧さやデータセットの編集に関する限られた透明性に起因して追加の監視を受けています。
3. **透明性と業種実践:**
DeepSeekはトレーニングデータやモデルアーキテクチャの詳細を完全に開示しておらず、西洋と中国の人工知能開発者の間で一般的な不透明性を反映しています(例:OpenAIがGPT-4のトレーニングデータを限定的に開示していること)。この透明性の欠如は知的財産の責任を複雑にするが、悪事ではなく競争の慣習を反映しています。
4. **国内背景とイノベーション:**
DeepSeekは米中の技術的緊張の中で中国の人工知能自給自足を推進しています。中国のモデルはしばしば西洋の技術を模倣していると非難されることがありますが、DeepSeekの技術的調整(たとえば、中国語環境や地域固有のアプリケーションに最適化することなど)は、地域に特化した革新を示しており、グローバルな研究基盤に基づいているとしても、地元でのイノベーションを示しています。
**結論:**
DeepSeekの開発は標準的な人工知能業界の慣行に従い、オープンソースのリソース、公共データ、および段階的な改善を組み合わせています。知的財産懸念は妥当ですが、これは人工知能の倫理とデータ利用に関するより広範な議論の一部です。不正コードやデータの不正使用の明確な証拠がない限り、批判はDeepSeekを特定するのではなく、システムの問題(たとえばトレーニングデータの著作権の遵守)に焦点を当てるべきです。このモデルは、人工知能の進歩の協力的性質と急速に進化している分野の知的財産慣行を航行する上での課題を表しています。
juz coz スレ主 : 法的なことに立ち入る必要はありませんが、明らかに言えることは、DeepSeekは低価格で開発されたわけではなく、誤解を招くように主張されているように、(密輸された)低性能のGPUを使用してゼロから作られたわけではありません。他のプラットフォーム(高性能のGPUを使用した)からコードやデータを引き出さなければ、DeepSeekはそのプラットフォームを"上回る"ことはできなかったでしょう。